OS LLM eval
Caveat OS LLM prompt templating is a nightmare. USER/ASSISTANT, User/Assistant, ### Instruction/### Response, one or two linefeeds, following : or not, …… Sorting that out takes more time than running these tests! Results that seem out of whack to you may be the result of my using the wrong prompt for that model.
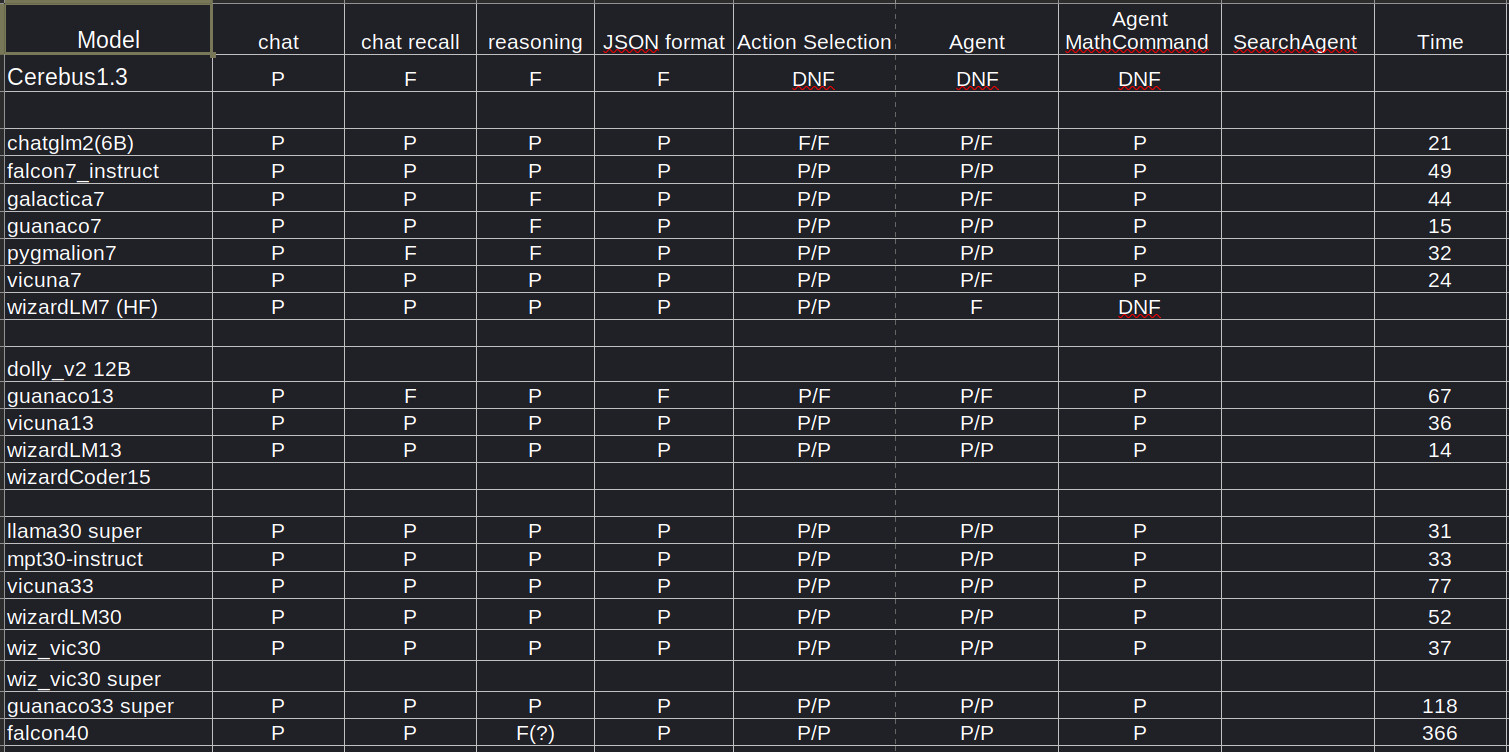
To use a smaller LLM for anything more than a chatbot, it needs some basic capabilities. The above simple spreadsheet shows results from running a simple test script on a few LLMs I can host locally. These tests do NOT evaluate the quality of results, only the ability to return a properly formatted response (well, not quite - chat recall, reasoning, and Agent must return semantically valid results)
It is a work in progress.
-
‘chat’ is just the ability to reply to a chat, just to make sure the server is running.
-
‘chat recall’ is the ability to correctly recall information provided earlier in the prompt.
-
‘reasoning’ is the ability to return the correct result on a simple theory of mind puzzle question. A proxy for the kind of reasoning needed to select a command to execute, or other simple reasoning task. It uses a simple ‘think step-by-step’ prompt
-
‘json one-shot’ is the ability to return an answer in a simple json format with one-shot training, alphawave repair allowed. an LLM passes if it can successfully repair an initial bad response syntax.
-
‘Action Selection’ is the ability to select an appropriate command from a small set and return the correct JSON syntax. Both syntax and command set errors (eg, hallucinations of non-existant commands) must be repaired within retry limit, thus P/P
-
‘Agent’ goes one step further. The LLM must not only select the correct action, but must also supply the correct argument syntax. Extras points (a + mark) if the LLM correctly translates the “square root” text in the input into “sqrt()”.
-
Everything above is using only plain AlphaWave. The next two use the full Alphawave Agent framework with its built-in prompt and command-repair mechanisms. Full points only if the agent correctly chains the action command with the finalAnswer command to actually present the result to the user. These are the most complex and demanding tests. The Agent framework includes a one-shot example of using the math command, so that is a slightly easier (maybe) first test.
-
‘Agent MathCommand’ tests the ability of the LLM to use alphawave’s Math command to solve a simple arithmetic calculation. This combines all the skills above: a more complex structured prompt, requiring a json formatted response that selects the math command to perform the required calculation, along with a valid python expression to evaluate. Finally, for full points, the LLM must successfully then respond to a subsequent query with an instruction to call the finalAnswer command to present the result.
-
‘SearchAgent’ is similar, but expects the agent to figure out it probably doesn’t know about today’s weather, so it better use search.
-
-
tbd:
- More small LLMs. What would you like to see next?
- Also, as you can see, I’m still having some server hosting issues on larger models.
- Larger command sets. too easy to pick a command when you have only one. (although hallucination repair frequently occurs, and is part of alphawave-agents)
- ‘super’ means a more recent model with Kaiuo Ken’s SuperHOT. I’m especially suspicious I’m running these right.
Disclaimer:
Some will, with good reason, object to my referring to models such as LLaMa, Vicuna, etc as ‘OS’. That’s fair. All I mean by that is they are available to the community. Alphawave-py is my retirement hobby, not an income source, so my use in strictly non-commercial.